







































Custom AI Agent Development for US Businesses: Complete Guide
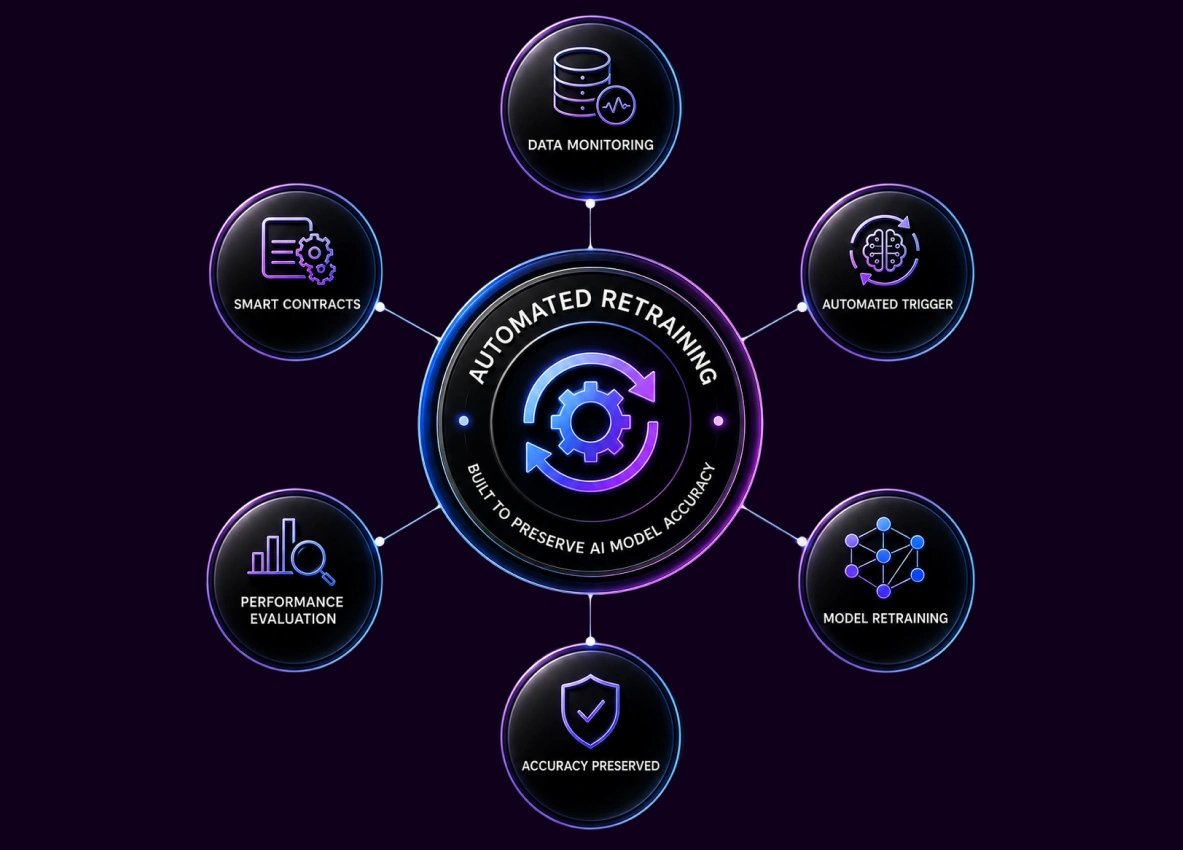
Key Takeaways Custom AI agents are purpose-built for enterprise workflows, integrating with internal systems like ERP, CRM, and data pipelines for intelligent automation. Unlike generic chatbots, custom AI agents can execute multi-step tasks autonomously, maintain contextual memory, and adapt to business-specific processes. Businesses across the U.S. are using AI agents to reduce operational costs, improve productivity, enhance compliance, and deliver 24/7 business support. Core features of enterprise AI agents include advanced workflow automation, persistent memory, AI voice integration, secure API connectivity, and SOC 2-compliant architecture. Industries such as healthcare, finance, logistics, retail, legal, and manufacturing are rapidly adopting AI agents for automation, predictive operations, and personalized customer experiences. Successful AI…


